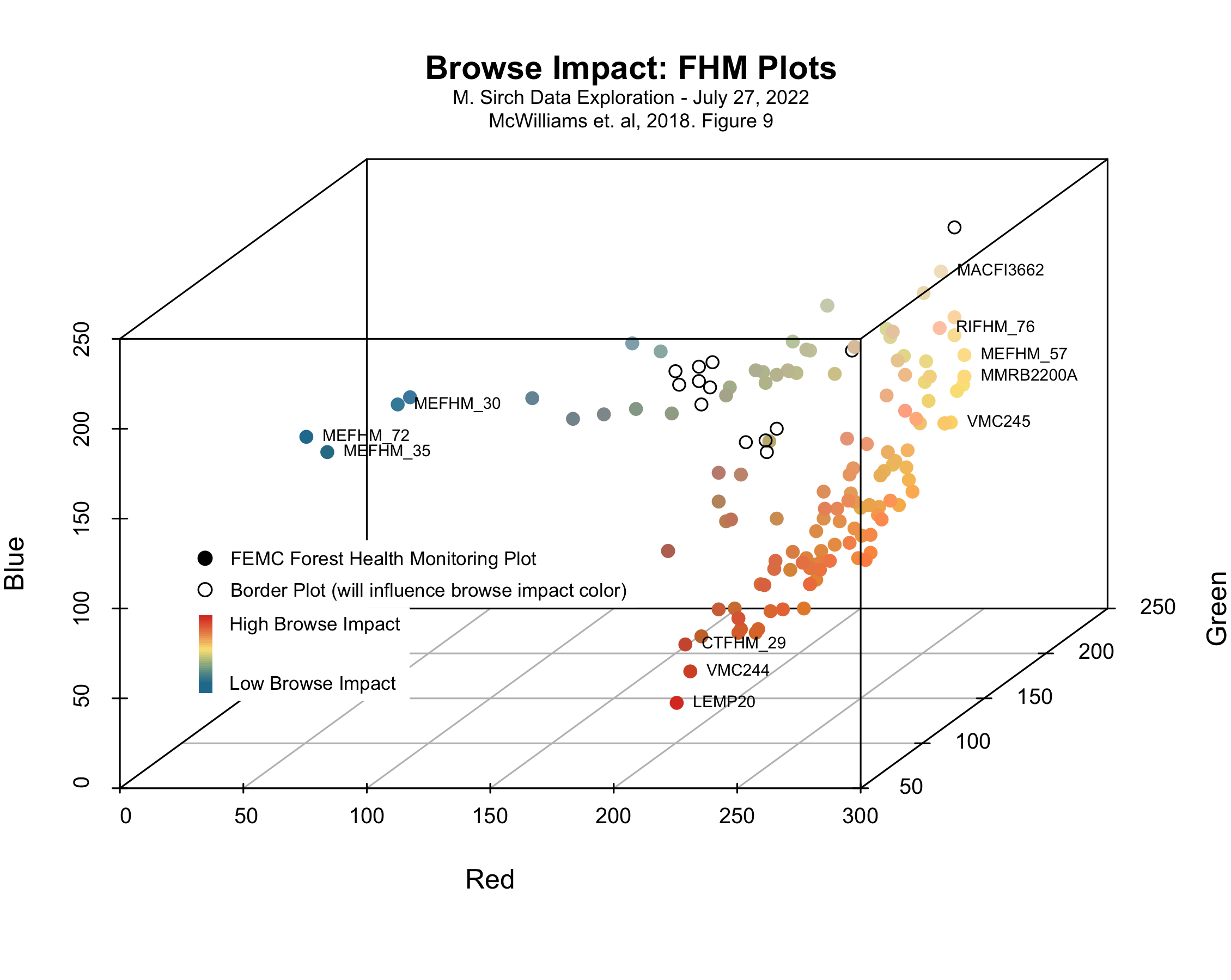
#################################
### FEMC Code for Annual Reports ###
### Forest Health Monitoring ########
#################################
# Matthias Sirch 9/20/2022
#
###################
## Table of contents ##
## SETTING A WORKING DIRECTORY Line 51 ##
## PREPARING LOOKUP TABLES Line 63 ##
## MERGING THE FHM EXPORT FILES Line 176 ##
## MERGING TREE DATA Line 178 ##
## MERGING SAPLING FILES Line 281 ##
## MERGING SEEDLING FILES Line 326 ##
## CREATING A REPORT DATAFRAME Line 346 ##
## CURRENT YEAR STATS Line 249 ##
## PLOT COUNT BY STATE Line 263 ##
## TREE COMPOSITION Line 295 ##
######################
# code written by Matthias Sirch August 2022
# 2021 data were retreived by Xana Wolf from "vmc_fhm" and "vmc_fhmma" databases on May 02 2022
###############################################################################################
# Coding Notes:
# this may all look like a lot, but R essentially runs one code line at a time
# open this file in RStudio for a more intuitive coding interface
# add comments (using #) throughout the code as needed to make the code
# easier to understand the next time someone uses it
# if you edit the code, keep the original and save a new version of the file
### BEGIN! ###
# you will be working out of one folder (your working directory)
# on your desktop, create a folder called "FHMStats"
# copy over the current year fhm and fhmma export files into a folder called "Archive" within the new FHMStats folder
# also copy over: dieback.xls, species.xls, transparency.xls files from the FHM Reports folder (TBD)
## SETTING A WORKING DIRECTORY ##
# set working directory to the folder that contains the FHM exported data and look up tables
# your path name ("/Users/...") will be different. Right click your FHMStats folder to find its path
# to run code, move cursor anywhere on the code line or the comments above the code
# and press ctrl+Enter on Windows, command+Enter on Mac
# one line of code at a time. Most code relies on code lines that have run before it
# you'll know it has run successfully when a new ">" appears
# if you need to stop the code or reset the > you can press Esc
setwd("/Users/matthiassirch/Desktop/FHMStats")
## PREPARING LOOKUP TABLES ##
options(scipen=100000) #set scientific notation
rm(list = ls(all=TRUE))
# to be able to upload the following lookup tables
# you'll need to install a package called "readxl"
#install.packages("readxl") #takes 30 seconds. You may need to type in "Yes" and then press Enter in the Console below
#
#
#
require(readxl) #requires R to use the program you just installed
# now you can read in the xls files (as "dataframes") that you dropped in the FHMStats folder
species<-read_xls("species.xls")
# if you're curious what one of the dataframe looks like
# you can run View(species) at any point along the way, where species is a dataframe
# in this species dataframe, let's change the name of column 1 to SpeciesCode
colnames(species)[1] <- 'SpeciesCode'
# let's remove the "Name" column
# we're actually replacing our species dataframe with a new subset that does not include the column "Name"
species<-subset(species, select = -c(Name)) # WILL
View(species)
# make the "CommonName" column lowercase
species$CommonName<-tolower(species$CommonName)
# substitute "american" for "American"
CommonName<-sub("american","American",species$CommonName)
# remove old CommonName column
species<-subset(species, select = -c(CommonName))
# add in the new CommonName column
species<-cbind(species,CommonName)
# we no longer need the CommonName column we created
# found under Values on the right of the screen so we'll remove rm() it
rm(CommonName)
# create these next two dataframes using only code
crownclass<-data.frame("item" = c(1:5),"value" = c("open growth","dominant","codominant","intermediate","suppressed/overtopped"))
defoliation<-data.frame("item"=c(0:3),"value"=c("None to trace defoliation","Less than 30 percent of crown defoliated","30 to 60 percent defoliation","Greater than 60 percent of crown defoliated"))
# our next two reference tables (dieback and transparancy) require a bit more scripting!
# lets create a 'vector' called Value to hold the new values we will create
# the c() refers to our columns which are empty here
Value<-c()
# the for(){} function can do a lot of work for us
# it could have been written as "for(i in 1:19){Value[i]<-i*5}"
# but indenting will help us keep track of what statements are nested in which function
# for each iteration we will multiply our value (i) by 5 from 1 through 19
# i here is just a variable and could've been named whatever you like
for (i in 1:19){
Value[i]<-i*5
}
# look what you just created!
# you're totally coding right now
# View(Value)
# let's add a 0 to our list
Value <- append(Value,0)
# we can now create a new description list by using paste0() which leaves no space between values
# we're pasting together each value - 4 using the value from column Value
# then " - ", then our value as it appears in column Value, and finally the "%"
Desc<-paste0(Value-4," - ",Value,"%")
View(Desc)
# combine our two lists by column binding (rbind()) Desc to our Value list
item<-cbind(Value,Desc)
# we're ready to convert our vector matrix to a dataframe
item<-data.frame(item)
# Alright, let's fix our table that has Value 0 described as "-4 - 0%"
# these two lines change description to "None" when Value is 0
levels(item$Desc) <- c(levels(item$Desc), "None")
item$Desc[item$Value==0] <- "None"
# lastly, let's add a new row named item2 that contains value 99 described as "96 - 100%"
item2 <- data.frame(Value = "99",Desc = "96 - 100%")
# and row bind (rbind()) item2 to our original item
item<-rbind(item,item2)
# we can make our two new data.frames using the item we just created!
dieback<-item
transparency<-item
# rm() removes lists and dataframes we no longer need
rm(Desc,i,item,item2,Value)
# you can also export a dataframe by running
# write.csv(crownclass,"/Users/matthiassirch/Desktop/FHMStats/test.csv",row.names=FALSE)
# where crownclass is the dataframe, "/Users/..." is the export location, and row.names=FALSE
# removes a column that would count the row number
## MERGING THE FHM EXPORT FILES ##
## MERGING TREE DATA ##
# "TreeHealth_fhm" here is a new dataframe you're creating
# from the csv file. The file uses ";" to separate rows
# notice we're accessing the csv files within the Archive folder
TreeHealth_fhm<-read.csv("Archive/vmc_fhm_export_table_tblTree.csv",sep=";")
TreeHealth_fhmma<-read.csv("Archive/vmc_fhmma_export_table_tblTreeVisit.csv",sep=";")
# removes columns from Subplot style plots (fhm) to match data export from Large style plots (fhmma)
# keep track of when you use code to remove columns. If you run this multiple times it will keep
# removing columns 21 through 53 and 56 through 59 of the updated dataframe
# if you run column removals more than once by mistake, return to code that created the original
# dataframe (in this case the read.csv("...")) and start from there
# if you are ever unsure, it doesn't hurt to View(TreeHealth_fhm) the dataframe
TreeHealth_fhm<-TreeHealth_fhm[-c(21:53,56:59)]
# fhm will need a TreeID that includes the subplot number
TreeID<-paste(TreeHealth_fhm$SubplotID,TreeHealth_fhm$TreeID)
TreeID<-data.frame(TreeID)
TreeHealth_fhm<-cbind(TreeID,TreeHealth_fhm)
TreeHealth_fhm<-TreeHealth_fhm[-c(4,5)]
# rearrange columns
TreeHealth_fhm<-TreeHealth_fhm[c(2,3,1,4:21)]
# combine fhm and fhmma. With the new TreeID as a factor type, fhmma will also need to be a factor
TreeHealth_fhmma$TreeID<-as.factor(TreeHealth_fhmma$TreeID)
TreeHealth<-rbind(TreeHealth_fhm,TreeHealth_fhmma)
rm(TreeHealth_fhm,TreeHealth_fhmma,TreeID)
## PLOT INFO ## nothing new here, files not used
# PlotInfo_fhm<-read.csv("vmc_fhm_export_table_tblPlotInfo.csv",sep=";")
# PlotInfo_fhmma<-read.csv("vmc_fhmma_export_table_tblPlotInfo.csv",sep=";")
## TREE INFO ## we'll need to add the species codes for each tree using the treeSppID files
treeSppID_fhm<-read.csv("Archive/vmc_fhm_export_table_tblTreeInfo.csv",sep=";")
treeSppID_fhmma<-read.csv("Archive/vmc_fhmma_export_table_tblTreeInfo.csv",sep=";")
# create tree IDs again for these fhm treeSppID files that contain the subplot number
TreeID<-paste(treeSppID_fhm$SubplotID,treeSppID_fhm$TreeID)
TreeID<-data.frame(TreeID)
treeSppID_fhm<-cbind(TreeID,treeSppID_fhm)
treeSppID_fhm<-treeSppID_fhm[-c(3,4)]
treeSppID_fhm<-treeSppID_fhm[c(2,1,3:6)]
treeSppID_fhmma<-treeSppID_fhmma[-3]
# combine fhm and fhmma. With the new TreeID created as a factor data type, the fhmma TreeID column
# will also need to be a factor
treeSppID_fhmma$TreeID<-as.factor(treeSppID_fhmma$TreeID)
treeSppID<-rbind(treeSppID_fhm,treeSppID_fhmma)
rm(treeSppID_fhm,treeSppID_fhmma,TreeID)
# combine TreeHealth and treeSppID
TreeHealth_identifier<-paste(TreeHealth$PlotID,TreeHealth$TreeID)
TreeHealth_identifier<-data.frame(TreeHealth_identifier)
TreeHealth_identifier<-cbind(TreeHealth_identifier,TreeHealth)
treeSppID_identifier<-paste(treeSppID$PlotID,treeSppID$TreeID)
treeSppID_identifier<-data.frame(treeSppID_identifier)
treeSppID_identifier<-cbind(treeSppID_identifier,treeSppID)
TreeHealth<-merge(TreeHealth_identifier,treeSppID_identifier)
rm(TreeHealth_identifier,treeSppID,treeSppID_identifier)
TreeHealth<-TreeHealth[-c(3,8,23)]
TreeHealth<-TreeHealth[c(1,2,21,3,4:15,17,16,19,20,23,22,24,18)]
# add states column
State<-substr(TreeHealth$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
States<-data.frame(State)
TreeHealth<-cbind(States,TreeHealth)
rm(State,States)
# finally, make sure there are no duplicate rows
# dplyr contains functions like "dinstinct" that can manipulate dataframes
#install.packages("dplyr") # type Yes and press Enter
#
#
#
require(dplyr)
TreeHealth<- distinct(TreeHealth)
#############################################
################# SAPLINGS ##################
#############################################
## MERGING SAPLING FILES ##
#we will now do the same thing to the sapling and seedling files
sapling_fhm<-read.csv("Archive/vmc_fhm_export_table_tblSapling.csv",sep=";")
saplingInfo_fhmma<-read.csv("Archive/vmc_fhmma_export_table_tblSaplingInfo.csv",sep=";")
saplingVisit_fhmma<-read.csv("Archive/vmc_fhmma_export_table_tblSaplingVisit.csv",sep=";")
# Create fhmma sapling ID identifier to combine the two fhmma sapling tables
saplingInfo_fhmma_identifier<-paste(saplingInfo_fhmma$PlotID,saplingInfo_fhmma$SubplotID,saplingInfo_fhmma$SaplingID)
saplingInfo_fhmma_Identifier<-data.frame(saplingInfo_fhmma_identifier)
saplingInfo_fhmma_Identifier<-cbind(saplingInfo_fhmma_Identifier,saplingInfo_fhmma)
saplingVisit_fhmma_identifier<-paste(saplingVisit_fhmma$PlotID,saplingVisit_fhmma$SubplotID,saplingVisit_fhmma$SaplingID)
saplingVisit_fhmma_Identifier<-data.frame(saplingVisit_fhmma_identifier)
saplingVisit_fhmma_Identifier<-cbind(saplingVisit_fhmma_Identifier,saplingVisit_fhmma)
sapling_fhmma<-merge(saplingVisit_fhmma_Identifier,saplingInfo_fhmma_Identifier)
rm(saplingInfo_fhmma,saplingVisit_fhmma,saplingInfo_fhmma_identifier,saplingVisit_fhmma_identifier,saplingInfo_fhmma_Identifier,saplingVisit_fhmma_Identifier)
sapling_fhmma<-sapling_fhmma[c(1,5,2,3,11,12,13,14,6,7,8)]
# combine sapling_fhmma with sapling_fhm
sapling_fhm<-read.csv("Archive/vmc_fhm_export_table_tblSapling.csv",sep=";")
sapling<-rbind(sapling_fhm,sapling_fhmma)
# this actually ran successfully! The warning here is saying it didn't like that the
# Species, Azimuth, and Distance were factors in one file and integers in another
# it resolved this issue for us by forcing the second dataframe listed here to match the first
# all this info, as well as number of columns (variables) and rows (observations),
# is listed for each dataframe in the Environment tab in RStudio
# View(sapling) to see that both fhm (NH, RI, VT) and fhmma (CT, MA, ME, NY) plots are in here
# add states column
State<-substr(sapling$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
States<-data.frame(State)
sapling<-cbind(States,sapling)
# cleaning up dataframes
rm(sapling_fhm,sapling_fhmma,State,States)
#############################################
################# SEEDLINGS #################
#############################################
## MERGING SEEDLING FILES ##
seedling_fhm<-read.csv("Archive/vmc_fhm_export_table_tblSeedling.csv",sep=";")
seedling_fhmma<-read.csv("Archive/vmc_fhmma_export_table_tblSeedling.csv",sep=";")
seedling<-rbind(seedling_fhm,seedling_fhmma)
# again, warning notifies you that some variable data types were changed when combined
# View(seedling) to see that both fhm (NH, RI, VT) and fhmma (CT, MA, ME, NY) plots are in here
# add states column
State<-substr(seedling$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
States<-data.frame(State)
seedling<-cbind(States,seedling)
rm(seedling_fhm,seedling_fhmma,State,States)
#######################################################
## CREATING A REPORT DATAFRAME ##
# Now that the file management is out of the way, let's create a Report dataframe
# that will contain all of our interesting statistics
Report<-data.frame(Page=character(),Section=character(),Category=character(),Type=character(),States=character(),YearRange=character(),Result=character())
# add new lines to the report dataframe using
# NewLine <- data.frame("Category"="can be text","States"=OrDataframeName,"YearRange"="","StatType"="","Stat"="","Result"="")
# Report<-rbind(Report,NewLine)
# export your report stats using
# write.csv(Report,"/Users/matthiassirch/Desktop/FHMStats/Report.csv",row.names=FALSE)
#######################################################
### CURRENT YEAR STATS ###
EndYear<-2021 #change the year to the final year of FHM data included, and then run this line of code
#######################################################
### PLOT DIMENSIONS ##
# Plot #
FHM_SubplotStyle_ac<-0.16616689624
FHM_LargeStyle_ac<-0.20030096419
# Microplot #
FHM_SubplotStyle_micro_ac<-0.01333951
FHM_LargeStyle_micro_ac<-0.01038543
#######################################################
# Select a state and/or species to see stats below for the given criteria
# to undo subsets, run lines 109 to 184 again
# subset species
# View(species) to find SpeciesCode
# TreeHealth<-subset(TreeHealth,Species=="318")
# subset states
# TreeHealth<-subset(TreeHealth,State=="VT" | State =="CT")
# subset years
# TreeHealth<-subset(TreeHealth,Year==2019:2021)
###############################################################################
### SUMMARY STATS ###
###############################################################################
# from now on, when there is this break the code should work independently
# as long as the code above has run successfully
###############################################################################
## PLOT COUNT BY STATE ##
###############################################################################
# In 2021, FEMC visited 153 plots from CT (13), MA (25), ME (34), NH (25), RI (7), and VT (49).
TreeHealth_current<-subset(TreeHealth, Year==EndYear)
# current year plot count
PlotCount<-as.data.frame(unique((TreeHealth_current$PlotID)))
colnames(PlotCount)<-c("PlotID")
State<-substr(PlotCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
States<-data.frame(State)
PlotCount<-data.frame(append(States,PlotCount))
rm(States,State)
PlotCount<-as.data.frame(table((PlotCount$State)))
colnames(PlotCount)<-c("State","PlotCount")
# number of states
StateNum<-length(PlotCount$State)
# This code will loop State and PlotCount using StateNum
# to give us a sentence that includes the right punctuation e.g. CT (13), MA (25), and ME (34).
# if there are two states then we need to include " and " between them
# or else we will include ", " and ", and" "." in the appropriate places
# in a nutshell:
# x<-1
# if(states==2){repeat{if(){" and "} x=x+1 if(x==states){break}}}else{repeat{if(){", "}if(){", and "}if(x==states+1){"." break}}}
# x here will serve as a counter, running x=x+1 after each repeat{}
x <- 1
# prepare a 'vector' named text to collect outputs from each repeat{} and if() statement
text <- character()
# instead of a single long line of code, I can indent
# keep indents organized so you can tell which statement is nested in which function
if(StateNum==2) {
repeat {
output <- paste0(PlotCount[x,"State"]," (",PlotCount[x,"PlotCount"],")")
text <- c(output)
if (x == 1){
output <- " and "
text <- c(text,output)
}
x = x+1
if (x == StateNum){
break
}
}
output <- paste0(PlotCount[x,"State"]," (",PlotCount[x,"PlotCount"],").")
text <- c(text, output)
}else{
repeat {
output <- paste0(PlotCount[x,"State"]," (",PlotCount[x,"PlotCount"],")")
text <- c(text,output)
if (x < StateNum-1){
output<-", "
text <- c(text,output)
}
if (x == StateNum-1){
output<-", and "
text <- c(text,output)
}
x = x+1
if (x == StateNum+1){
output<-"."
text <- c(text,output)
break
}
}
}
# we made a list that includes all the right ingredients
# now we paste them together with nothing ("") between each item
PlotResults<-paste(text,collapse="")
# this code creates a row that we can add to our report dataframe
# In 2021, FEMC visited 153 plots from CT (13), MA (25), ME (34), NH (25), RI (7), and VT (49).
PlotStats <- data.frame("Page"="4","Section"="Executive Summary","Category"="Plot","Type"="Count","States"=paste(unlist(PlotCount$State),collapse=", "),
"YearRange"=EndYear,"Result"=paste0("In ",EndYear,", FEMC visited ",
sum(PlotCount$PlotCount)," plots from ",PlotResults))
# print() shows us what's in the Result column of PlotStats in the console below
print(PlotStats$Result)
Report<-rbind(Report,PlotStats)
# write.csv(Report,"/Users/matthiassirch/Desktop/FHMStats/Report.csv",row.names=FALSE)
# clean up dataframes
rm(output,PlotCount,PlotResults,PlotStats,StateNum,text,TreeHealth_current,x)
###############################################################################
### TREE COMPOSITION: Species Composition
###############################################################################
# Results from the 2021 monitoring season indicate that red maple (15%), balsam fir (14%), and sugar maple (10%) were the most abundant species within the monitoring plots.
TreeHealth_current<-subset(TreeHealth, Year==EndYear)
PlotCount<-as.data.frame(unique((TreeHealth_current$PlotID)))
colnames(PlotCount)<-c("PlotID")
State<-substr(PlotCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
States<-data.frame(State)
PlotCount<-data.frame(append(States,PlotCount))
rm(States,State)
PlotCount<-as.data.frame(table((PlotCount$State)))
colnames(PlotCount)<-c("State","PlotCount")
## SPECIES FREQUENCY ##
Species<-data.frame((TreeHealth_current$Species))
Species_current<-as.data.frame(table(Species))
# merging the current species frequency list (Species_current) with the list of species names (species)
# using specified columns that share values (Species_current$Species and species$item)
Species_current<-merge(Species_current,species,by.x='Species',by.y="SpeciesCode")
# sorting columns. The - here will sort the Freq column in decreasing order
# you can sort multiple columns using e.g. z[order(-z$Freq,z$CommonName),]
Species_current<-Species_current[order(-Species_current$Freq),]
# sum of tree counts using the Freq column of Species_current
TotalTrees_current<-sum(Species_current$Freq)
# this code computes the Freq row of Species_current but total count of trees * 100 to get the percent
# we use round(,digits=0) to display results with no decimal places
Species_percent<-round(((Species_current$Freq)/(TotalTrees_current)*100),digits=0)
Species_percent<-as.data.frame(Species_percent)
Species_current<-cbind(Species_current,Species_percent)
# REPORT #
# Results from the 2021 monitoring season indicate that red maple (15%), balsam fir (14%), and sugar maple (10%) were the most abundant species on average within the monitoring plots.
PlotStats <- data.frame("Page"="4","Section"="Executive Summary","Category"="Tree","Type"="Composition","States"=paste(unlist(PlotCount$State),collapse=", "),
"YearRange"=EndYear,"Result"=
paste0("Results from the ",EndYear," monitoring season indicate that ",
Species_current[1,"CommonName"]," (", Species_current[1,"Species_percent"],"%), ",
Species_current[2,"CommonName"]," (", Species_current[2,"Species_percent"],"%), and ",
Species_current[3,"CommonName"]," (", Species_current[3,"Species_percent"],
"%) were the most abundant species within the monitoring plots."))
print(PlotStats$Result)
Report<-rbind(Report,PlotStats)
# write.csv(Report,"/Users/matthiassirch/Desktop/FHMStats/Report.csv",row.names=FALSE)
rm(PlotCount,PlotStats,Species,Species_current,Species_percent,TotalTrees_current,TreeHealth_current)
###############################################################################
### TREE COMPOSITION: Tree density
###############################################################################
# From the 6,936 trees (>5 inch DBH) measured, average live overstory tree density in 2021 was 191 stems/ac and 127 ft²/ac basal area.
TreeHealth_current<-subset(TreeHealth, Year==EndYear)
## TOTAL TREE COUNT ##
TreeCount_measured<-sum((table(TreeHealth_current$TreeID)))
# add a comma for large numbers (e.g. "6,936" instead of "6936")
TreeCount_measured<-format(TreeCount_measured, big.mark = ",", scientific = FALSE)
## LIVE TREES PER ACRE ##
# not all dead trees were measured
# live trees only (having vigor 1 through 4, '|' meaning 'or')
TreeHealth_live<-subset(TreeHealth_current, Vigor==1 | Vigor==2 | Vigor==3 | Vigor==4)
# plot count used to calculate acreage surveyed
PlotCount<-as.data.frame(unique(TreeHealth_live$PlotID))
colnames(PlotCount)<-c("PlotID")
State<-substr(PlotCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
PlotCount<-data.frame(table(State))
colnames(PlotCount)<-c("States","PlotCount")
# live tree count
TreeCount<-as.data.frame(TreeHealth_live$PlotID)
colnames(TreeCount)<-c("PlotID")
State<-substr(TreeCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
TreeCount<-data.frame(table(State))
colnames(TreeCount)<-c("States","TreeCount")
# plot count and tree count
TreesPerAcre<-merge(PlotCount,TreeCount)
# area of each plot for every state
PlotArea_ac<-ifelse(grepl("NH|RI|VT",TreesPerAcre$State), FHM_SubplotStyle_ac, FHM_LargeStyle_ac)
PlotArea_ac<-data.frame(PlotArea_ac)
TreesPerAcre<-cbind(TreesPerAcre,PlotArea_ac)
# get total plot area surveyed for each state
AreaSurveyed_ac<-TreesPerAcre$PlotCount * TreesPerAcre$PlotArea_ac
# total area surveyed per state
TreesPerAcre<-cbind(TreesPerAcre,AreaSurveyed_ac)
# get total area survey in acres
AreaSurveyed_total<-sum(TreesPerAcre$AreaSurveyed_ac)
# total live tree count
TreeCount_total<-sum(TreesPerAcre$TreeCount)
# live trees per acre
TreesPerAcre_ALL<-TreeCount_total/AreaSurveyed_total
# round to no decimal
TreesPerAcre_ALL<-round(TreesPerAcre_ALL,digits=0)
## BASAL AREA ##
# it's tempting to just add all DBH together and get area from that diameter
# but that will give us an area much larger than it should be
# we'll instead convert DBH to area one tree at a time
# make one DBH column from modified and traditional DBH measurements
DBH<-ifelse(TreeHealth_live$DBH_Modified=="NULL",paste0(TreeHealth_live$DBH_Traditional),paste0(TreeHealth_live$DBH_Modified))
TreeHealth_live<-cbind(TreeHealth_live,DBH)
# cm to ft
DBH_ft<-as.numeric(DBH,na.rm=FALSE)*0.0328084
# this code ran successfully, no worries here
TreeHealth_live<-cbind(TreeHealth_live,DBH_ft)
# radius of trees
Radius<-as.numeric(DBH_ft)/2
TreeHealth_live<-cbind(TreeHealth_live,Radius)
# R squared
R2<-Radius^2
TreeHealth_live<-cbind(TreeHealth_live,R2)
# R squared x pi
R2pi<-R2*pi
TreeHealth_live<-cbind(TreeHealth_live,R2pi)
# sum basal area while ignoring NA values
BasalArea<-sum(TreeHealth_live$R2pi,na.rm=TRUE)
# Basal area per acre
BasalArea_ac<-BasalArea/AreaSurveyed_total
# total tree area (basal area)
BasalArea_ac<-round(BasalArea_ac,digits=0)
# ADD TO THE REPORT! #
# From the 6,936 trees (>5 inch DBH) measured, average live overstory tree density in 2021 was 191 stems/ac and 127 ft²/ac basal area.
TreesPerAcreStat <- data.frame("Page"="4","Section"="Executive Summary","Category"="Tree","Type"="Density","States"=paste(unlist(PlotCount$State),collapse=", "),
"YearRange"=EndYear,"Result"=paste0("From the ",TreeCount_measured,
" trees (>5 inch DBH) measured, average live overstory tree density in ",
EndYear," was ",TreesPerAcre_ALL," stems/ac and ",BasalArea_ac," ft²/ac basal area."))
print(TreesPerAcreStat$Result)
Report<-rbind(Report,TreesPerAcreStat)
rm(BasalArea,BasalArea_ac,AreaSurveyed_ac,AreaSurveyed_total,DBH,DBH_ft,R2,R2pi,TreeHealth_current,Radius,State,PlotArea_ac,TreeCount,TreeHealth_live,TreesPerAcreStat,PlotCount,TreeCount_measured,TreeCount_total,TreesPerAcre,TreesPerAcre_ALL)
# write.csv(Report,"/Users/matthiassirch/Desktop/FHMStats/Report.csv",row.names=FALSE)
###############################################################################
### REGENERATION: Saplings
###############################################################################
# Regeneration assessments show sapling densities of 511 live stems per acre with balsam fir and American beech representing the most abundant species across the 153-plot network.
sapling_current<-subset(sapling, Year==EndYear)
# live sapling stems per acre
sapling_live<-subset(sapling_current,sapling_current$SaplingStatus==1)
# frequency table
# we can use the State column here because each sapling has its own row
sapling_count<-table(sapling_live$State)
# turn into dataframe
sapling_count<-data.frame(sapling_count)
# sum frequency column
sapling_count<-sum(sapling_count$Freq)
# Plot list of every state
TreeHealth_current<-subset(TreeHealth, Year==EndYear)
PlotCount<-as.data.frame(unique(TreeHealth_current$PlotID))
colnames(PlotCount)<-c("PlotID")
State<-substr(PlotCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
PlotCount<-data.frame(table(State))
colnames(PlotCount)<-c("States","PlotCount")
# area of a given MICROPLOT in each state
PlotArea_ac<-ifelse(grepl("NH|RI|VT",PlotCount$State), FHM_SubplotStyle_micro_ac, FHM_LargeStyle_micro_ac)
PlotArea_ac<-data.frame(PlotArea_ac)
Plots<-cbind(PlotCount,PlotArea_ac)
# get total plot area surveyed for each state
AreaSurveyed_ac<-Plots$PlotCount * Plots$PlotArea_ac
Plots<-cbind(Plots,AreaSurveyed_ac)
# get total area survey in acres
AreaSurveyed_total<-sum(Plots$AreaSurveyed_ac)
# sapling count per acre
SaplingPerAcre<-sapling_count/AreaSurveyed_total
# rounding saplings per acre
SaplingPerAcre<-round(SaplingPerAcre,digits=0)
# sum plot count column in the plot count dataframe
PlotCount_total<-data.frame(sum(PlotCount$PlotCount))
## SAPLING SPECIES FREQUENCY ##
Species<-data.frame((sapling_live$Species))
Species_current<-as.data.frame(table(Species))
# merging the current species frequency list (Species_current) with the list of species names (species)
# using specified columns that share values (Species_current$Species and species$item)
Species_current<-merge(Species_current,species,by.x='Species',by.y="SpeciesCode")
# sorting columns. The - here will sort the Freq column in decreasing order
# you can sort multiple columns using e.g. z[order(-z$Freq,z$CommonName),]
Species_current<-Species_current[order(-Species_current$Freq),]
View(Species_current)
# sum of tree counts using the Freq column of Species_current
TotalTrees_current<-sum(Species_current$Freq)
# this code computes the Freq row of Species_current but total count of trees * 100 to get the percent
# we use round(,digits=0) to display results with no decimal places
Species_percent<-round(((Species_current$Freq)/(TotalTrees_current)*100),digits=0)
Species_percent<-as.data.frame(Species_percent)
Species_current<-cbind(Species_current,Species_percent)
# REPORT #
# Regeneration assessments show sapling densities of 551 live stems per acre with balsam fir and American beech representing the most abundant species across the 153-plot network.
SaplingsPerAcreStat <- data.frame("Page"="4","Section"="Executive Summary","Category"="Sapling","Type"="Density, Composition","States"=paste(unlist(PlotCount$State),collapse=", "),
"YearRange"=EndYear,"Result"=paste0("Regeneration assessments show sapling densities of ",SaplingPerAcre," live stems/acre with ",
Species_current[1,"CommonName"]," and ",Species_current[2,"CommonName"]," representing the most abundant species across the ",PlotCount_total,"-plot network."))
print(SaplingsPerAcreStat)
Report<-rbind(Report,SaplingsPerAcreStat)
rm(PlotArea_ac,PlotCount,PlotCount_total,Plots,sapling_current,sapling_live,SaplingsPerAcreStat,Species,Species_current,Species_percent,TreeHealth_current,AreaSurveyed_ac,AreaSurveyed_total,sapling_count,SaplingPerAcre,State,TotalTrees_current)
###############################################################################
### REGENERATION: Seedlings (work in progress!)
###############################################################################
# Red maple was the most abundant seedling tallied in 2019 (42.12% composition, 7,294 SPA), followed by sweet birch (22.30%, 3,861 SPA), and striped maple (6.2%, 1,074 SPA) (Table 11).
# Seedling densities were calculated to be 17,318 stems per acre, on average, with red maple and sweet (black) birch representing the most abundant seedling species.
seedling_current<-subset(seedling, Year==EndYear)
# examine only the Count column
seedling_count<-seedling_current$Count
# sum seedling count
# we need to convert our seedling_count 'factor' to character and then to numeric
# it's a good habit to check your work by hand to see if results line up
# na.rm = True removes null values
seedling_total<-sum(as.numeric(as.character(seedling_count)), na.rm = TRUE)
# SURVEY AREA and STATE LIST #
# area of each plot for every state
TreeHealth_current<-subset(TreeHealth, Year==EndYear)
PlotCount<-as.data.frame(unique(TreeHealth_current$PlotID))
colnames(PlotCount)<-c("PlotID")
State<-substr(PlotCount$PlotID,1,2)
State<-ifelse(grepl("FE|HH|LB|LE|MM|NA|VM",State), "VT", State)
PlotCount<-data.frame(table(State))
colnames(PlotCount)<-c("States","PlotCount")
# area of a given MICROPLOT in each state
PlotArea_ac<-ifelse(grepl("NH|RI|VT",PlotCount$State), FHM_SubplotStyle_micro_ac, FHM_LargeStyle_micro_ac)
PlotArea_ac<-data.frame(PlotArea_ac)
Plots<-cbind(PlotCount,PlotArea_ac)
# get total plot area surveyed for each state
AreaSurveyed_ac<-Plots$PlotCount * Plots$PlotArea_ac
Plots<-cbind(Plots,AreaSurveyed_ac)
# get total area survey in acres
AreaSurveyed_total<-sum(Plots$AreaSurveyed_ac)
# seedlings per acre
SeedlingPerAcre<-seedling_total/AreaSurveyed_total
# rounding seedlings per acre
SeedlingPerAcre<-round(SeedlingPerAcre,digits=0)
# add a comma for large numbers (e.g. "23,180" instead of "23180")
SeedlingPerAcre<-format(SeedlingPerAcre, big.mark = ",", scientific = FALSE)
## SEEDLING SPECIES FREQUENCY ##
seedling_current<-subset(seedling, Year==EndYear)
View(seedling_count)
seedling_count<-seedling_current[!is.na(seedling_current$Count),]
seedling_count$Count<-as.integer(as.character(seedling_count$Count))
Count<-with(seedling_count,tapply(as.numeric(Count),as.character(Species),FUN=sum))
seedling_count <- data.frame("SpeciesID"=rownames(Count),Count)
seedling_count<-merge(seedling_count,species,by.x='SpeciesID',by.y="SpeciesCode")
seedling_count<-seedling_count[order(-seedling_count$Count),]
Species_percent<-seedling_count$Count/seedling_total*100
seedling_count<-cbind(seedling_count,Species_percent)
Variable<-round(seedling_count[2,"Species_percent"],digits=0)
# REPORT #
# Seedling densities were calculated to be 17,318 stems per acre, on average, with red maple and sweet (black) birch representing the most abundant seedling species.
SeedlingsPerAcreStat <- data.frame("Page"="4","Section"="Executive Summary","Category"="Seedling","Type"="Density, Composition","States"=paste(unlist(PlotCount$State),collapse=", "),
"YearRange"=EndYear,"Result"=paste0("Seedling densities were calculated to be ",SeedlingPerAcre," seedlings per acre with ",
seedling_count[1,"CommonName"]," (",round(seedling_count[1,"Species_percent"],digits=0),"%, ",format(round((seedling_count[1,"Count"]/AreaSurveyed_total),digits=0), big.mark = ",", scientific = FALSE)," stems/ac) and ",
seedling_count[2,"CommonName"]," (",round(seedling_count[2,"Species_percent"],digits=0),"%, ",format(round((seedling_count[2,"Count"]/AreaSurveyed_total),digits=0), big.mark = ",", scientific = FALSE)," stems/ac) being the most abundant seedling species."))
print(SeedlingsPerAcreStat)
Report<-rbind(Report,SeedlingsPerAcreStat)
View(Report)
rm(AreaSurveyed_ac,AreaSurveyed_total,Count,PlotArea_ac,PlotCount,Plots,seedling_count,seedling_current,seedling_total,SeedlingPerAcre,SeedlingsPerAcreStat,Species_percent,State,TreeHealth_current)
# write.csv(Report,"/Users/matthiassirch/Desktop/FHMStats/Report.csv",row.names=FALSE)